Why Data Science?
So what is Data Science? Why this field that comes from nowhere suddenly become the most popular carreer? Data itself has been cheap, free, spread across the internet. Earlier back in the days, companies just keep data from themselves. And this make it rare and expensive. But turns out, the data that they only have, is not so much if they want to see it from the bigger picture. This is why they need more data, from other sources. They can't keep learn from the data that they only have. Generated more data can be easy. But it need people who can get insights from huge number of sources. 90% of the data created from the last two years. This of course can't keep up with existing people that already in the field. And suddenly world need data scientist.

Data Science could be scrapped all the data free on the internet. Take a look at the MoneyBall example, where they have this statistics. It spend quarter of payroll paid by New York Yankees to its team, and achieve almost same winning to NYY.Or fivethirtyeight.com that successfully predicted voting U.S president. Or how about Netflix prize competition for those whoever try to beat more than 10% of their accuracy. They used Latent Factors Model, to recommend move from users that hahave similar type of you.You can also see ad-targetting, which may creep you. Google use your email, and try to find out what you need. They deliver ad-banner related to content of your email. There are so many fields that need Data Science.
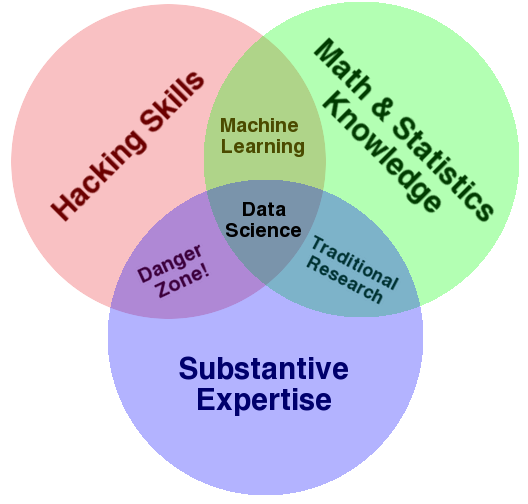
Some said Data Science is just buzzwords for statistician. This is not trully true. Data Science not come for the analysis part itself, but also whole process from scrapping the data, decide what data and question to ask, exploratory data analysis, and build model and communicate our finding. What's dificult is messy data that we have, wrangling,munging,auditing the data so it can be clean. And manipulate the data into meaningful information. Data Wrangling is not something learned by statistics.
They pressumed that the data receieved is clean data. While in reality that 99% of the data has input error. This example, have to deal with missing data. Or how about we have to extract source from various source and data formats. You may have others said 70% the work of Data Scientist lies on wrangling the data, this boring and dirty process. It need the skill level of Software Engineer to do the wrangling process. After that, we have to decide if we want to remove outliers in our data.
Based on key principles of Data Science, on CS109 Harvard, here are some concepts:
- Science. How you learn based on experience, based on other data scientist that share their knowledge. Learn which can be answered through data, and which the best datasets to answer the question.
- Computer programming. Use computer to analyze the data. We do this using various tools, programming language like python, its library, like scikit-learn for machine learning, Amazon for computing Engine, or Hadoop Cluster, or github for saving repository.
- Data Wrangling. What is the general term for scrapping. The idea is we gather all data from various sources, from the internet. Cleaning, munging, and auditing the data, so it clean and can be used for analyzing.
- Statistics. Using exploratory data analysis, descriptive, inference statistice to get insights of the data. We may want to know if this is regression,classification, using Bayes probabiliy.
- Machine Learning. Using this to predict the data, there are some famous out there. Naive Bayes for classification, Support Vector Machine for regression. Boosting, k-nearest neighbors.
- Communication. Communicate our finding, we do this after we have perform our analysis and insight. And want to share it to the people.