Hadoop and Big Data
In our engineering world, nowadays we familliar with the term of Big Data. Big Data itself is . But is everything is about Big Data? Details about smartphone owned by a person for a phone company may not a Big Data, but hundreds of person may be a Big Data. Big Data comes from a different perspective. Some said that Big Data is used terrabytes of data. Others said that Big Data is data that is so big, it couldn't fit on the single machine.
According to IBM: "Every day, 2.5 billion gigabytes of high-velocity data are created in a variety of forms, such as social media posts, information gathered in sensors and medical devices, videos and transaction records"
Big Data is a loosely defined term used to describe data sets so large and complex that they become awkward to work with using standard statistical software. (International Journal of Internet Science, 2012, 7 (1), 1–5)
Data is created fast, really fast. You can google it and there are source that said 90% of the data generated, is created since 2012. Data comes from different source in various format. There are many format like XML,JSON,CSV (you might want to check my other blog post). For most data, it's important for Data Scientist what's the most valuable information, have insights for datasets, where others find it worthless.
3V¶
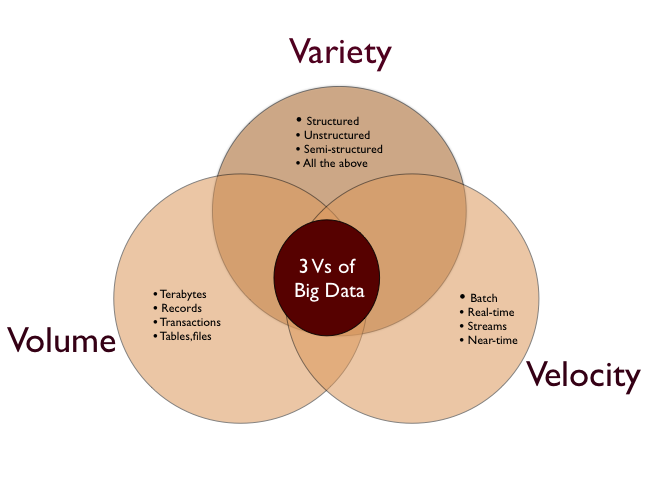
(Image: Courtesy of Kavy Muthana)
3V is Volume, Variety, and Velocity. Volume is what often called by what are the data size that we have. Variety, where our data comes from different sources in different formats. Velocity is what are the speed in which our data generated. All data is useful and is up to us as a Data Scientist, to bring a value from it. Hadoop is one tools that is often used whenever company want to scale the data down.
The 3 V's were first defined in a research report by Douglas Laney in 2001 titled "3D Data Management: Controlling Data Volume, Velocity and Variety". In 2012 he updated the definition as follows "Big data is high volume, high velocity, and/or high variety information assets that require new forms of processing to enable enhanced decision making, insight discovery and process optimization".
The problem to store the data to various database like Oracle, MySQL, or others, is that they have predefined structure. That is often not the case for most data, that comes from unstructured ones. Variety, for example. The problem for that is you may want to store conversation in phone company, as a Text, or audio. All leads to different path to use. Hadoop can handle it on what we want to convert the data from. The data may change as we needs and store it back to Hadoop. Many data types and structure, as defined in terms of Variety, can squeezed any information we need from the data, that can be useful to address the problem that we currently need.
The final is Velocity. Your data may come terrabytes a day. You might end up discarding unused data in your storage. This could end up badly, if your data tends to be more valuable in the future in case you want to need it. You need to store all this so you could enhance your systems, or sales.
Hadoop¶
Doug Cutting, the Creator of Hadoop, and the Chief Architect at Cloudera, adress a problem, where back then he can't do an efficient computing for 2 to 4 machine. So he then began the research and found google processing frameworl. Doug then along with his friend create an open source project that implementing paper research by Google. This create Hadoop, where it then can scale well from 20 to 40 machines. But to make that a bulletproof scales to petabytes for thousands of machine couldn't be just done by two people. So Yahoo get interest on it, invest on Hadoop and becomes what it is now. Sort of operating systems that has can perform some Map Reduce SQL, scales flexibly on thousands of machines. Funny name that Hadoop comes from Doug's son toy elephant. His son called it Hadoop, strange name that reminds Doug in business, can be unique and coincidentally comes with the maskot.
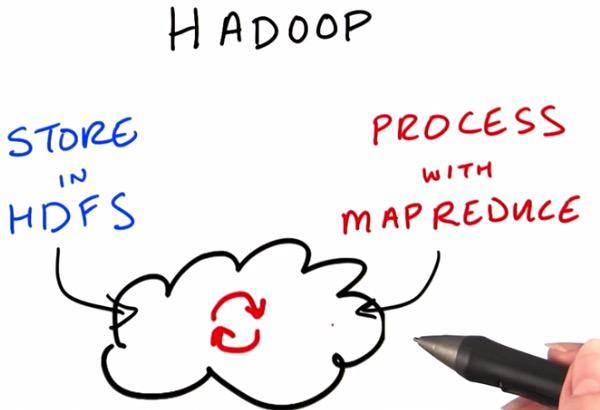
For all the data that we are about to store, Hadoop Distributed File System will store our data in the cloud, where physically divided by range of cluster. The process the data that we have stored, we process it with Map Reduce algorithm. This traditionally live in the single central server, where Hadoop can process it by cluster. Mid-range equipment should do just fine rather than top tier equipment.
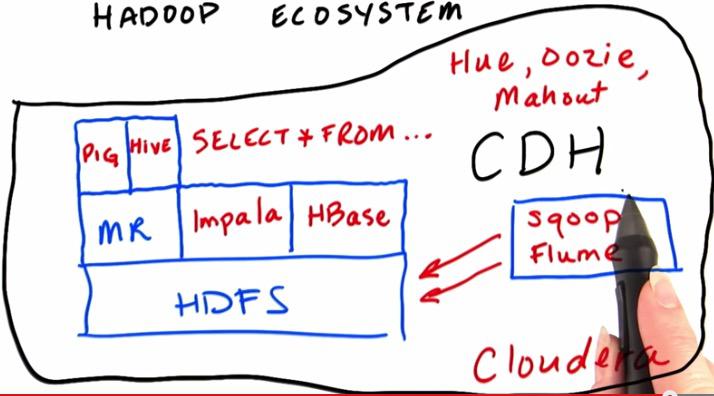
Hadoop at its core in the beginning only consist of MapReduce algorithm and Hadoop Distributed File System. Over time, to simplify this ecosystem, all software created to support this. With programmer that know how to write programming language like Java, Python, Ruby, they can write Map Reduce algorithm to access HDFS. If there's people that really not into programming language, they can use scripting language like Pig or Hive. Hive acts like SQL, that encapsulate all Map Reduce process, so people can form any process to HDFS using SQL.Pig is used to analyze large datasets.
Or maybe people just doesn't want into MapReduce. They prefer to extract it directly into HDFS. For this, they have impala. Like query SQL also, but without MapReduce they have low latency. While Hive is designed to have long batch processing, there is tools like Sqoop that acts to eliminate files in HDFS. HBase acts like a real database that store and process in HDFS.
There are also other libraries like Hue, Oozie, Mahout - acts as a machine learning library. All tools built in Hadoop Ecosystem can be installed with CDH, Cloudera Distribution with Hadoop. It's a package that far easier installed rather than installing tools one by one.
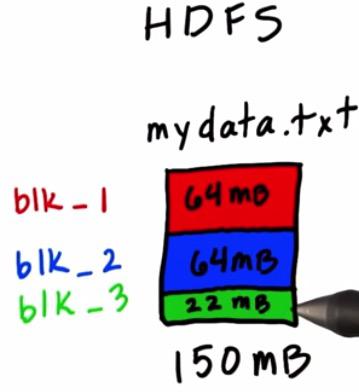
When you have a file, let's say mydata.txt. This data has 150mb file size. The data store in the HDFS. HDFS will fragment your data to blocks, with prefix "blk". These blocks will then divide that into HDFS cluster, that will contains n cluster of machine. It will store data required. So you can have m blocks of data, and n cluster of machine. Not all machine can have your data. These cluster machine called Data Nodes. To manage all this thing together, we still need one machine that map key to value of your cluster. This machine called Name Node. Name Node will abstract complexity of managing cluster in your Hadoop cluster. These will introduce a new problem, whether your Data Nodes or your Name Node have disk failure, or your Data Nodes have network failure.
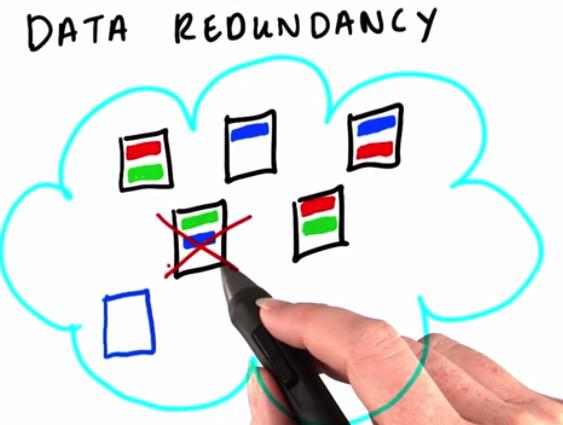
For HDFS, data could also suffer data redundancy. Suppose you have one block of code that reside in machine have some failure. Then the data itself could be missing, there will be presented a hole in the middle of your data. To prevent this HDFS will replicate your data, three times, across different cluster. So each cluster will has different replicate blocks of data. In this case, even if you have one machine failure, you still have back-up data. This still left with one problem, what if this the case where you have Name Node failure, the one that map key value across different machine? Your data could be inaccessible, worse, your data could be lost forever. HDFS however, will replicate your data, if there are data failure. This are checked by daemons that running continuously on your machine.
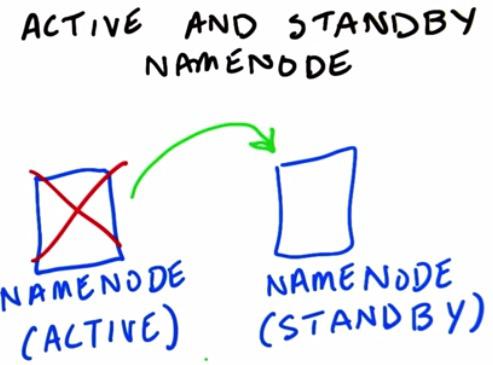
Name Node could be be potentially broken. This will cause problem stated earlier. One way to avoid this is to create NFS, we could store the image, copy of of namenode in our hadoop file system. Or the alternative way, is to create one standby backup of Namenode. That way, if the active one is broken, the standby could replace it until it remains active.Of course, of everything else, could be provided NameNode on a better high-end hardware.
RESOURCES :
- http://blogs.gartner.com/doug-laney/files/2012/01/ad949-3D-Data-Management-Controlling-Data-Volume-Velocity-and-Variety.pdf
- http://static.googleusercontent.com/media/research.google.com/en/us/archive/gfs-sosp2003.pdf
- http://static.googleusercontent.com/media/research.google.com/en/us/archive/mapreduce-osdi04.pdf
- http://go.cloudera.com/udacity-lesson-1
- https://www.udacity.com/course/viewer#!/c-ud617/l-306818608/m-309273679