Design Study

Statistic is really a thing to take serious consideration. Evidence that taking from skewed sample is Anecdotal evidence, which assume only very particular cases. It is when generalizing to the mode trend of the data, we can see more generalized summary.
In Statistic, mostly we divide into following components:
- Research question
- Population
- Sample
- Generalize
In the case of research to analyze certain alcohol impact, the targeted population is everyone that drink alcoholic. Turns out, because the sample only taken from ER at Hospital in Baltimore, it can only generalize to Residents of Baltimore.
Thing to consider is design, what's best question to approach the problem,, and the scope of the variables, whether the relation is correlation or causation.
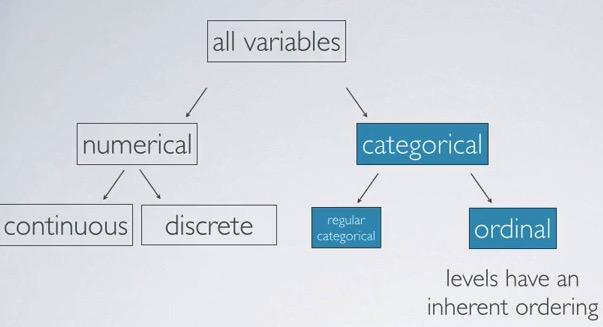
- Identifying each of the type of variable of data your working with is the first step in EDA.This will make you easier to choose which kind analysis you want to do.

- Relationship of the two variable.
- If connected called as
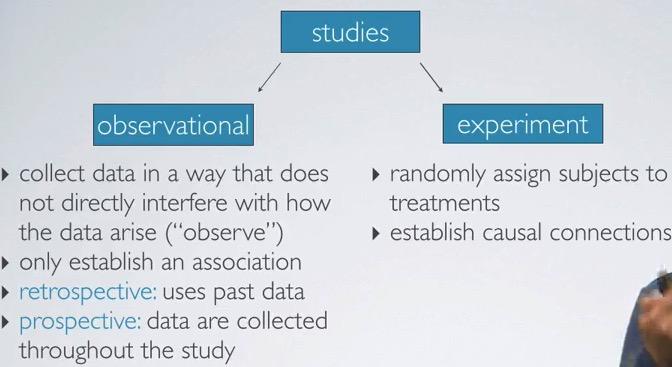
We can divide studies into observational and experiment
The Observational studies, you can see the corellation of the data, but can't make causation of the data, since you don't control the lurking variables.You make past data, and see the relationship when you are generate data throughout your studies.
On the other hand, in the experiment, you can control all lurking variables, that is the variables that potentially missing from your attention. If we control all this, we can make causation between explanatory variable and the response variables.
In the controlled experiment,For example workout vs not workout, you randomly assigned group of people into two group, thus randomly divided people that maybe category divided(gender, body shape) into equal quantity, then you make an experiment. On the contrary, because you don't randomly assigned in Observational Studies, your object experiment will be skewed. And because of that, you're missing the lurking variables, the people's category, and can't make causation.Lurking variables, often called Confounding variables, is what makes it clear distinct that correlation can't make causation.

Why not use just entire population and sample it?
Census will require a lot of resources, with time and money. People could also missing the location. Some people maybe in very deep urban area, or people that hard to measure, like illegal immigrants that don't want to fill out the survey.Population could also hard to be static, as we know they change location overtime.

There are few categories that we can defined bias when we're doing sampling from the population. Let's take raise of cost of the public transport at your city for example.
- Convenience Sample : This are the sample that you do, when you do only in your neighborhood, and not the entire city. So people in your neighborhood will likely many more than others in the rest of the city
- Non-response : The people that you're asking with is never take the public transport, so they don't answer with your survey. This could means that these people(not random) won't give the answer making you have non-response bias
- Voluntary response : These are the people that using public transport only recently, and they have strong opinions about the issue. It maybe a little too strong, compared to the rest of categories in your city.
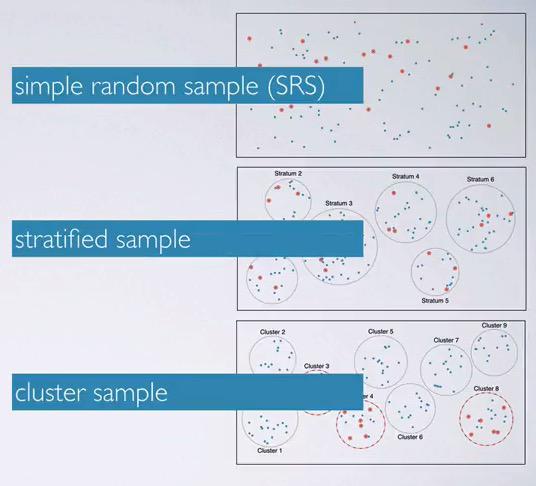
There are usually three kinds of method, when you're doing sampling
- SRS: These are the samples when you randomly pick sample out of whole population
- Stratified : We divide the population into groups, then sampling it from the groups. For example, groups the population with men vs women, and sample from each groups
- Cluster : We cluster the population, and see if there's clusters that similar, only pick one cluster and sample from those. These happen when you don't want to explore entire population that will be take a lot of resources.

- When doing simple random sampling, you can take random assignment.
- In Stratified sampling, even when you divide the neighborhood, you still can do sampling
- In Cluster sampling when it cluster based on neighborhood, you can't find similar neighborhood and only sample of these. It said that neighborhoods are distinct and unique, and avoid the one neighborhood will not be representative of the whole population.

When designing an experiment, these are the things that you should do.

Suppose that the gels maybe achieve diferently in pro and amateur. We block the status, divide them into pro and amater group, and divide it again to treatment and control.These way, there are 4 group that represented equally.

If the explanatory variables, is the independant variable, a quantify variable to measure the causation of our dependant variable.
On the other hand, blocking variables is the variable that we think will behave differently, a category variable, so we're gonna observe it too.
Response variable is a dependant variable, some score of accuracy that we're meassure.
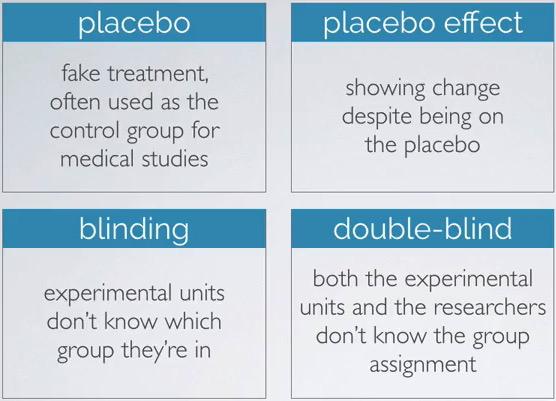
So if you're going to know whether the energy gels helps to increase people to run faster, you're divide into two groups, a group that receieve treatment, the energy gels, and second the group that receive placebo, fake treatment, and by doing this we don't give them energy gels. We're doing blinding method, the people we're doing experiment with don't know which treatment they're gonna get. Sometimes an experiment is done in double-blinding, the people and the researcher don't know the treatment and the placebo, to avoid favorite bias. Placebo effect would shown to the researchers what are lurking variables that help the people making run faster even without receiving the treatment

Random Sampling is taking sample from whole population, therefore the purpose is to take generalizablity to the population
Meanwhile Random Assignment serve to randomly assign each group of characteristic,to the treatment and the control.In other words, Random Assignment only come after Random Sampling.
The ideal experiment is when we can generalize to the whole population. But often it doesn't work that way. As we discussed earlier, sampling entire population is hard. So most experiment maybe doing causation for subset of population.
Observational studies that doesn't show any correlation and can't be generalize can't be used. On the other hand, if it show any correlation, then we can share it to the public.
RESOURCES :