validation with scikit-learn
With separate training and testing dataset, we would know how are the performance of our learning model against dataset that haven't been seen. In this way we know how our model generalize if there's new examples. It also acts as a background check whether your model is overfitting. It may cause dataset shortage, but it's kind of step that is worth for. Keep in mind that every machine learning algorithm fit in the training set, not in a test set. If you fit in a test set, and score also in the test set, you definitely would have high performance. And that's called tremendous CHEATING in machine learning.
evaluation with scikit-learn

Skewed Class is when the label is too scarce from the other label (suppose it's a binary classification). Takes POI for example, where the non POI is huge compare to POI. This would give imbalance label, and POI lacks train dataset for the learning model.
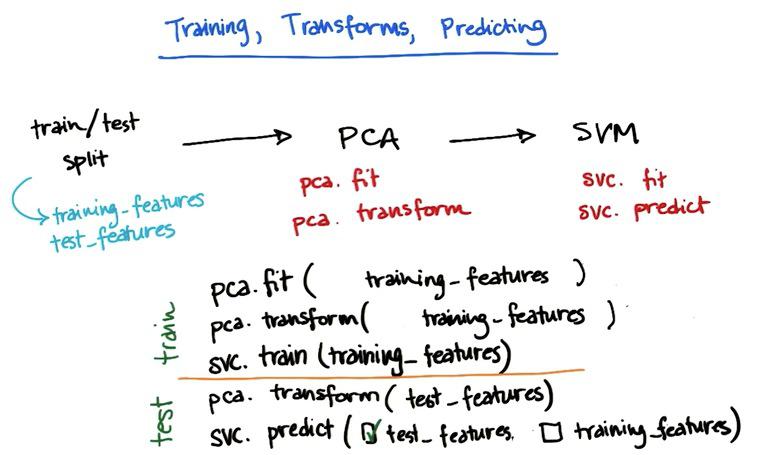
PCA with scikit-learn
PCA is used thoroughly for most of the time in visualization data, alongside feature set compression. It's hard (othwerwise impossible) to interpret the data with more than three dimension. So we reduce it to two/third dimension, allow us to make the visualization. This could come very handy if we want to capture the general information about the data, or to present it as business context. But it's not the tool that we use for combining two features, or compress it, as PCA throws some (important) information.
Feature Selection with scikit-learn

Feature Selection is one of thing that we should pay attention when building machine learning algorithm. For all features available, there might be some unnecessary features that will overfitting your predictive model if you include it. So choose best features that's going to have good perfomance, and prioritize that. On the other hand, we may don't see that some features, that we really need is missing (in the case of using EDA). What we want to do is synthesize a new feature based on features available.
Text Learning with scikit-learn
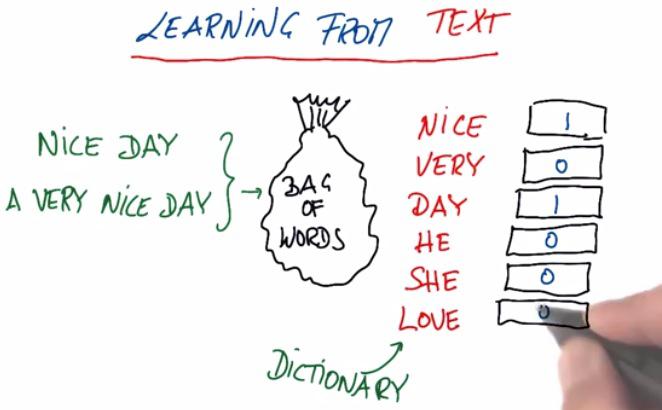
Text Learning, is machine learning on broad area which incorporate text. Many search giants, like Google, Yahoo, Baidu, tried to to learn text from various search. In this example we take a look at bag of words, which contains words, and from the data, count the frequency of word occurs in the text.
Feature Scaling with scikit-learn

Feature Selection is one important tool in Machine Learning.It's about how we normalize the range of each of our feature so that it can't dominate from one to another. Let's take this picture for example.
K-Means with scikit-learn
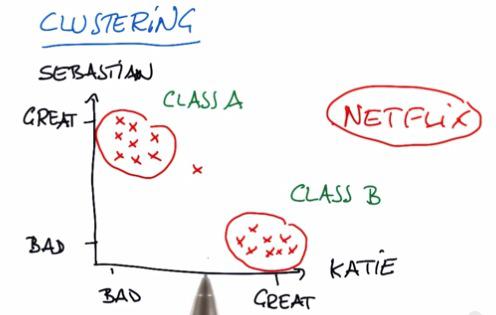
Clustering is one example of Unsupervised Learning. Unsupervised Learning is something that we want to learn from the datasets, eventhough we don't know what to label this particular data. This particular group in the plot,named cluster, is something that we want to learn this lesson. Dimensionality Reduction (PCA) also one of the Unsupervised Learning algorithm that I will be discussed in the future blog.
Outliers with scikit-learn

Outlier in datapoints is normally occurs. It probably some mistyped data from input of other people (e.g. 200 instead of 20). In this plot we see there's outliers that drawn outside the trend of the data. This cause the linear regression, if outliers included, to draw the linear model in such a terrible way. In this case, to best minimize the least squared error, the model would choose the top line.
Regression with scikit-learn
Supervised Learning has divided into 2 major category, classfication and regression. The classfication is where the machine learning algorithm predict discrete output, the regresion predict continuous output, hence often called Continuous Supervised Learning.
Datasets and Question
Enron is one of the tenth largest companies back in 2002 at U.S. This multi-billion dollar company suddenly collapsed and thousands of people losing their jobs, and some of them going to jail. This company have identified as corporate fraud, and go to bankruptcy as one of the most complex bankruptcy cases in U.S. history. The fraud was so massive and some may wonder why it lasted until 2001. Even Enron bankruptcy some said closely tied with 9/11 incident.