evaluation with scikit-learn

Skewed Class is when the label is too scarce from the other label (suppose it's a binary classification). Takes POI for example, where the non POI is huge compare to POI. This would give imbalance label, and POI lacks train dataset for the learning model.
Or, perhaps that you have some person that you're trying to purse whether the person innocent or guilty. If innocent, you really want to decide they're innocent, otherwise you put innocent person in jail. Likewise, you wouldn't put guilty person to be free when he should be jailed. This is something that you can be worked on based on the hunches.
Accuracy is not well suited for this.It assumes that labels varieties are equally distributed. As you don't have 50:50 labeled data, you don't get the score well based on accuracy. That's why evaluation metrics, precision-recall-f1 score that I will be discuss, is one of another important evaluation metrics that you should have in your arsenal. You want to know that, encountered in such rare cases, what are your performance.
Please check my other blog posts for more information about Precision,Recall and F1 Score.
Confusion Matrix¶
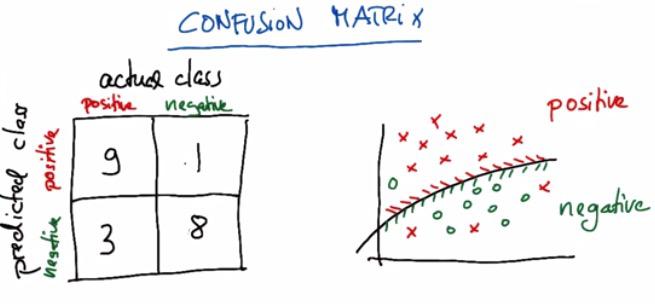
This a simple matrix of binary classification, spesifically tailored to value for precision and recall. The boundary classifier is the thing that we want to change. Will we want the classifier more to the positive, or to the negative. This is the tradeoff that we want to analyze based on our need, whether we want the model to circumvent more to particular label, or the other.
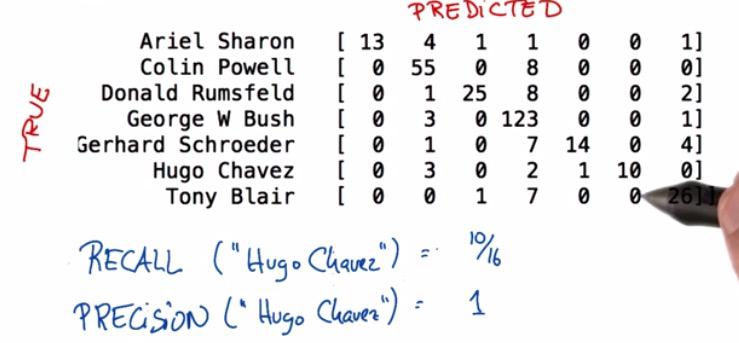
This it the matrix of predicted/true of U.S presidents. We can see the diagonal line, is when the predictions is actually true, and the rest is missclassify. Let's take Hugo Chavez for example. Over images being predicted by learning model, only 16 predict Hugo Chavez. On those 16, only 10 being the predicted. So Recall is, over all the predictions, what are the probability that predict Hugo Chavez actually correct. While the precision, is when the learning model meet Hugo Chavez's image, what are the probability that the learning model guess it correctly. In this case the recall Hugo Chavez leads 10/16, while the precision is 1, so the learning model perform perfectly when encountered with Hugo Chavez's picture.
TP, FP, FN¶
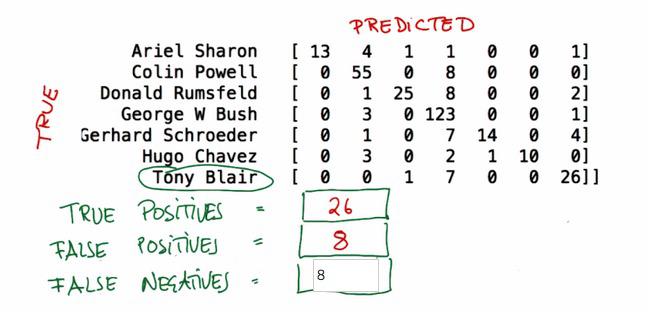
True positives is when the model thinks is positive, and it's actually true.
False positives is when the model thinks is positive, but it isn't (false).
False negatives is when the model thinks is negatives, but it isn't (false).

Mini Project¶
As usual, because this blog post are the note that I have taken from Udacity course, you can see the link of the course for this note at the bottom of the page. Here I attack some of the problem they have at their mini project.
Go back to your code from the last lesson, where you built a simple first iteration of a POI identifier using a decision tree and one feature. Copy the POI identifier that you built into the skeleton code in evaluation/evaluate_poi_identifier.py. Recall that at the end of that project, your identifier had an accuracy (on the test set) of 0.724. Not too bad, right? Let’s dig into your predictions a little more carefully.
%load ../evaluation/evaluate_poi_identifier.py
%load ../validation/validate_poi.py
# %%writefile evaluate_poi_identifier.py
"""
starter code for the validation mini-project
the first step toward building your POI identifier!
start by loading/formatting the data
after that, it's not our code anymore--it's yours!
"""
import pickle
import sys
sys.path.append("../tools/")
from feature_format import featureFormat, targetFeatureSplit
from sklearn.tree import DecisionTreeClassifier
from sklearn import cross_validation
data_dict = pickle.load(open("../final_project/final_project_dataset.pkl", "r") )
### add more features to features_list!
features_list = ["poi", "salary"]
data = featureFormat(data_dict, features_list)
labels, features = targetFeatureSplit(data)
features_train,features_test,labels_train,labels_test = cross_validation.train_test_split(features,labels,test_size=0.3,
random_state=42)
clf = DecisionTreeClassifier()
clf.fit(features_train,labels_train)
clf.score(features_test,labels_test)
How many POIs are in the test set for your POI identifier?
(Note that we said test set! We are not looking for the number of POIs in the whole dataset.)
clf.predict(features_test)
import numpy as np
print np.array(labels_test)
print len([e for e in labels_test if e == 1.0])
How many people total are in your test set?
print len(labels_test)
If your identifier predicted 0. (not POI) for everyone in the test set, what would its accuracy be?
1.0 - 5.0/29
As you may now see, having imbalanced classes like we have in the Enron dataset (many more non-POIs than POIs) introduces some special challenges, namely that you can just guess the more common class label for every point, not a very insightful strategy, and still get pretty good accuracy!
Precision and recall can help illuminate your performance better. Use the precision_score and recall_score available in sklearn.metrics to compute those quantities.
What’s the precision?
from sklearn.metrics import *
precision_score(labels_test,clf.predict(features_test))
What’s the recall?
(Note: you may see a message like UserWarning: The precision and recall are equal to zero for some labels. Just like the message says, there can be problems in computing other metrics (like the F1 score) when precision and/or recall are zero, and it wants to warn you when that happens.)
Obviously this isn’t a very optimized machine learning strategy (we haven’t tried any algorithms besides the decision tree, or tuned any parameters, or done any feature selection), and now seeing the precision and recall should make that much more apparent than the accuracy did.
recall_score(labels_test,clf.predict(features_test))
In the final project you’ll work on optimizing your POI identifier, using many of the tools learned in this course. Hopefully one result will be that your precision and/or recall will go up, but then you’ll have to be able to interpret them.
Here are some made-up predictions and true labels for a hypothetical test set; fill in the following boxes to practice identifying true positives, false positives, true negatives, and false negatives. Let’s use the convention that “1” signifies a positive result, and “0” a negative.
predictions = [0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1]
true labels = [0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0]
How many true positives are there?
predictions = [0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1]
true_labels = [0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 0]
What's the precision of this classifier?
precision_score(true_labels,predictions)
What's the recall of this classifier?
recall_score(true_labels,predictions)
Making sense of metrics¶
“My true positive rate is high, which means that when a POI is present in the test data, I am good at flagging him or her.”
“My identifier doesn’t have great precision, but it does have good recall. That means that, nearly every time a POI shows up in my test set, I am able to identify him or her. The cost of this is that I sometimes get some false positives, where non-POIs get flagged.”
“My identifier doesn’t have great recall, but it does have good precision. That means that whenever a POI gets flagged in my test set, I know with a lot of confidence that it’s very likely to be a real POI and not a false alarm. On the other hand, the price I pay for this is that I sometimes miss real POIs, since I’m effectively reluctant to pull the trigger on edge cases.”
My identifier has a really great F1 score.
This is the best of both worlds. Both my false positive and false negative rates are low, which means that I can identify POI’s reliably and accurately. If my identifier finds a POI then the person is almost certainly a POI, and if the identifier does not flag someone, then they are almost certainly not a POI.”
There’s usually a tradeoff between precision and recall--which one do you think is more important in your POI identifier? There’s no right or wrong answer, there are good arguments either way, but you should be able to interpret both metrics and articulate which one you find most important and why.