Using MapReduce and Design Pattern
MapReduce can handle all your process in the Hadoop File System. It broke your data into chunks that reside in each cluster, then perform your data in parallel way. Suppose we need hashtable and we use it to add key value to our hashtable. If there's millions data, we can be low on memory, out of memory perhaps. And the hashtable will be created after a long time. For this thing, parallel could be work.
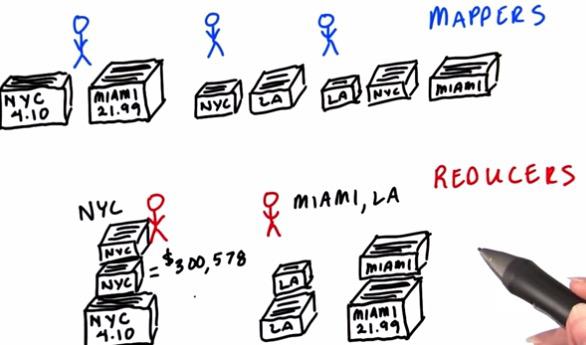
Supppose we have mappers and reducers that acts as a person. We want to collect from our files that contains all the sales in 2012. We want to know what is the total sales for each of the region. To do this we can assign number of machines that contains the data to same number that acts as a mappers. So each machine acts as a mapper. As data divided into chunks, these chunks have any region. Each of the mapper then will sum total sales for each of the region. This task are done in parallel for each of the cluster. After task for mappers are done, the reducers then will retrieve all the clusters result. Suppose there are two reducers, each of them tasked with a different region. Then the reducers will collect data related to them to each of the mapper. Then they are ready to total all of the sales. Since total sales already been calculated, they just sum total sales they collected from mappers.For each of the reducers, they have sorting order by alphabetical to make things easily. The task has much faster run time. And this is the core of MapReduce task.
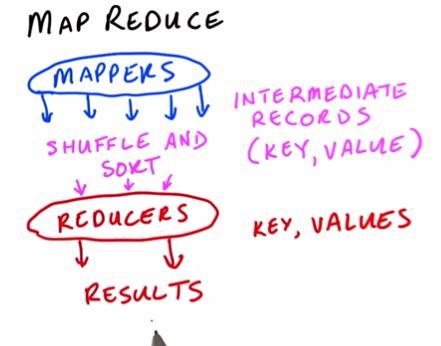
For all the mappers, the output will be called Intermediate Records that acts as a hashtable. It will then proceed to shuffle and sort to reducers, this is done automatically as part of the hdfs process. The reducers then, as it already assign for specific key, have one key contain value for all the mappers, and sum it. Then the reducers will return the final result. It's possible to have sorted order. All we have to do is assigne one additional reducer or perform extra step.But as to which keys divided for each reducers, we still don't know.
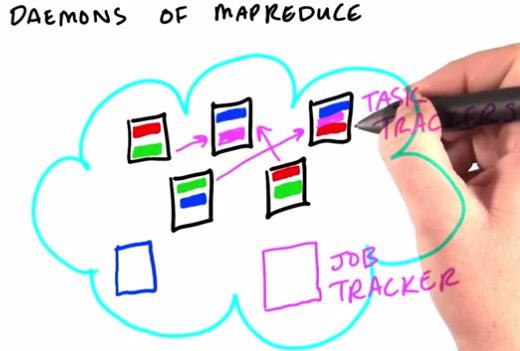
Daemons is a piece of code running continuously on each of the machine. When we created a job, we create a job tracker that split the mappers and reducers across different machines. There are daemon called Task Tracker, that live in each of the machine. It perform as a map task, making sure that it run all machine running task separately. This could reduce network traffic by significant. Each of the mapper after handling the task will be handed to assigned reducers. We can see same block of data at different machine. By default, HDFS replicates each chunk three times, across different machine for reliability.
RUNNING A MAPREDUCE JOB WITH THE VM ALIAS
hs {mapper script} {reducer script} {input_file} {output directory}MapReduce can be used in Machine Learning algorithm, such as fraud detection, recommender systems or else. Unfortunately, to use MapReduce, we have to change our paradigm when we used to write a code. This could be use a lot of pratice to get usual.Keep in mind, when performing MapReduce, HDFS will refuse to run if there are any existing output folder.

Almost MapReduce can be solved by using any of these templates.Filtering Pattern, used to sampling from all the datasets, or maybe choose top 10 out of the datasets. Or Maybe Summarization Patterns, we make some calculation based on the datasets. Make a prediction model, or statistics overview (min,max,mean,median), or create indexing. Or we build Structural pattern, when we combining datasets. These patterns can acts as a template if we are going to encounter the problems again in the future.
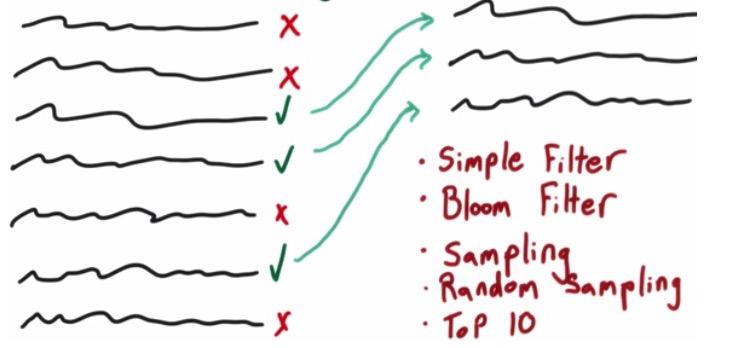
Filtering Patterns is one of the category that doesn't change the data in the datasets. The task is to keep or throw the data. It can be based on simple filter, with condition. Can be a Bloom Filter, a probabilistic filtering that worth mentioning. Sampling, which fetch portion of the data without any special condition. Random Sampling, different based on the sampling that it's completely random. Or just top-N sampling.
top-N is special case in Filtering Patterns. In RDBMS, you can easily makes sorted query or based on group by. This was not the case if you have many data spread through your cluster. What you want is create top-N in every mapper, and give to reducer to produce global top-N.
Summarization Patterns¶
This kind of patterns that we may use often if we are in data science field. It perform some mathematical process that for our data. There's numerical summarization, presenting some final value, mean,max,min,standard deviation. We use mapper to format our data needed to do mathematical process. Then do the calculation in the reducer.
Structural Patterns¶
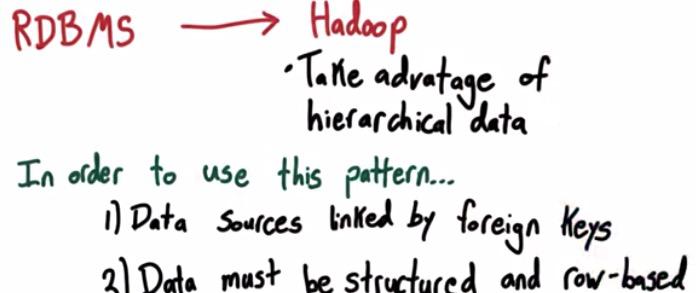
Structural Patterns is usually when you want to transfer your datasets from RDBMS to Hadoop, this taking the advantage of hierarchical data. But to do this you want your data to be linked by foreing keys, and structured in row-based.
RESOURCES:
- http://en.wikipedia.org/wiki/Bloom_filter
- http://hadoop.apache.org/docs/r2.2.0/api/org/apache/hadoop/util/bloom/BloomFilter.html
- https://www.udacity.com/course/viewer#!/c-ud617/l-713848763/m-705049026
- https://www.udacity.com/course/viewer#!/c-ud617/l-308873795/e-309271564/m-309271565
- https://developer.yahoo.com/hadoop/tutorial/module5.html#partitioning
- https://docs.google.com/document/d/1MZ_rNxJhR4HCU1qJ2-w7xlk2MTHVqa9lnl_uj-zRkzk/pub